
Friday 19th July was not a lot of fun, for quite a lot of people and that certainly included those at both Microsoft and Crowdstrike. As both organisations had incidents that had a significant impact on systems and people across the globe.
What happened?
Firstly, Microsoft, made some changes in their central US region, that did not act as expected and impacted Azure and M365 services. While it was identified quickly and fixes applied, it did still have global impact and meant service degradation for many customers. Secondly, CrowdStrike, had an issue with a content update. Like most security firms, it pushed out a content update to ensure its endpoint agent had the latest security intel, however, as their CEO
George Kurtz stated “The system was sent an update, and that update had a software bug in it and caused an issue with the Microsoft operating system”. That issue caused Windows devices to “Blue Screen”. While for many this meant not being able to access their devices and get on with their work. But it also had other wide-ranging effects, impacting multiple sectors, as it also impacted Windows-powered devices like kiosks, signage and control systems, making them unusable and causing services to fail and widespread disruption.
Questions
This article isn’t about pointing fingers, rather I just wanted to take a couple of minutes to ask, what has the events of Friday taught us?
Like with all incidents we should take some time to analyse what that incident means and what can we learn from it.
For me, it raised two obvious questions. Firstly resilience, both cases showed what can happen when we have all of our IT eggs in a single basket. Because if that service fails you, its impact can be significant. Secondly a question about update policies. As an industry, especially around cybersecurity, we advocate the importance of patching quickly. Some cybersecurity frameworks even dictate it. But what Friday showed is what can happen if a faulty update is pushed out.
Answers?
It’s very easy to jump into answer mode and state seemingly obvious answers to quite complex questions. It’s easy to say things like.
- You shouldn’t have your eggs in one basket.
- You shouldn’t use this vendor.
- You shouldn’t just roll out updates.
But the problem with these things is they are rarely that simple. For example, while not having all your eggs sounds sensible and maybe in future customers won’t use a single vendor across all its endpoints, or have all of its infrastructure in a single cloud provider. But it’s not quite as easy as it sounds and it does have implications. This will lead to increased complexity, increased operations overhead, and subsequently increased costs. Does that mean you shouldn’t do it? No, but it is also important to understand that these changes have consequences and as always is a balancing act.
All about risk
While there are no easy answers to this, what it does remind us, is that IT infrastructure resilience and risk are inextricably linked. And when we look at potential ways of mitigating the impacts we saw on 19th July, we need to balance that with risk. IT does not come with
guarantees. And while it's easy to point the finger at CrowdStrike or Microsoft, it's important to note, that the reality is that it could easily have been two other vendors.
We also need to be aware that mitigating these types of risks isn’t free, it comes with a cost and has to be judged against the constant IT cycle of;
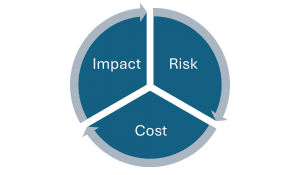
What’s the risk of something happening, what’s the impact of it happening and what’s the potential cost associated with it?
As an example, let’s apply this lens to “don’t just update”. The reason vendors like CrowdStrike apply these types of content updates is to ensure their endpoint tools are 100% up-to-date to deal with the very latest threats. Now, while we saw the impact of these sort of updates having an issue and it’s easy to say, well don’t update straight away. But what’s the risk of not having our security tools get the latest updates in a timely manner? Because, while the CrowdStrike incident was hugely impactful, the question to ask is, what’s the impact of not doing it, what risk does it pose and what is the potential cost of that risk? Is the cost of the risk of updating immediately, bigger than the risk of not doing it? Even as I write this, I realise there a nuances, even to this seemingly simple argument.
What to learn?
As a friend of mine Howard Holton highlights in his article Navigating the CrowdStrike outage, it “highlighted the vulnerabilities inherent in our interconnected world”. The fact that one failed update, impacted 1000’s of devices and 10’s of 1000’s of people needs to be something to learn from, not just for vendors, but equally for us as customers. We should ask ourselves a few simple questions.
- Where’s our risk?
- How do we mitigate the risks?
- What is the cost versus impact of these actions?
- And if all else fails, what do we do about it?
IT is complex and incidents like this are rare, but they can happen. If there is one positive we can take from this incident, it is we should all be able to learn from it. And, if we act upon what we learn, we will be better prepared for the next time.
Our team at Gardner Systems is ready to assist you in finding solutions that best fit your organisation's unique needs. For any queries or to discuss this in more detail, please do not hesitate to contact us.
Call us at 0151 220 5552, email us at Info@gardnersystems.co.uk or fill out a contact form here.








