This story is about an AI-driven consultant chatbot I have worked on based on LangChain and Chainlit. This bot asks potential customers about their problems in the enterprise data space, developing on the go a dynamic questionnaire to better understand the problems. After gathering enough information about the user’s problem, it gives advice to solve it. Whilst formulating questions it also tries to check if the user is confused and needs some questions answered. If that is the case, it tries to reply to it.
The chatbot is built around a knowledge base about topics related to AI governance, security, data quality, etc. But you could use other topics of your choice.
This knowledge base is stored in a vector database (FAISS) and is used at every step to either generate questions or give advice.
This chatbot could however be based on any knowledge base and used in different contexts. So it you can take it as a blueprint for other consulting chatbots.
Interaction Flow
The normal flow of a chatbot is simple: the user asks a question and the bot answers it and so on. The bot normally remembers the previous interactions, so there is a history.
The interaction of this bot is however different. It looks like this:
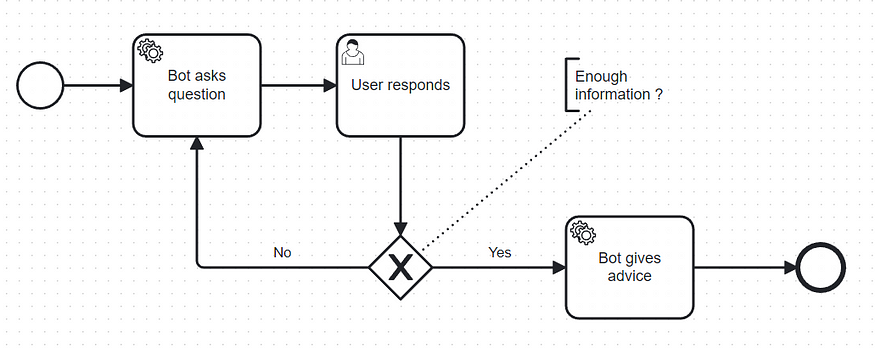
AI driven consultant chatbot interaction
In this case the chatbot asks a question, the user answers and repeats this interaction a couple of times. If the accumulated knowledge is good enough for a response or the number of questions reaches a certain threshold, a response is given, otherwise another question is asked.
Rough Architecture
Here are the participants in this application:
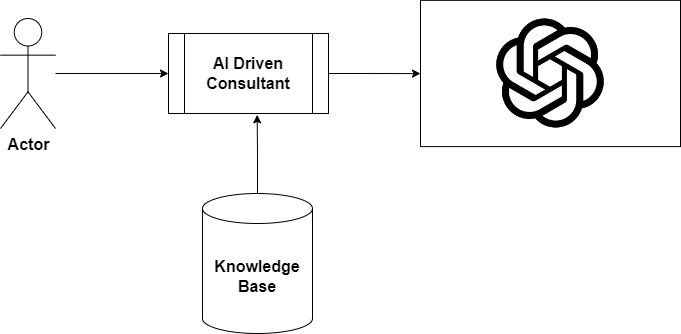
Main participants in the AI driven consultant chatbot
We have 4 participants:
The user
The application which orchestrates the workflow between ChatGPT, the knowledge base and the user.
ChatGPT 4 (gpt-4–0613)
The knowledge base (a vector database using FAISS)
We have tried ChatGPT 3.5 but the results were not that great and it was hard to generate meaningful questions. ChatGPT 4 (gpt-4–0613) seemed to produce much better questions and advices and be more stable too.
We have also experimented with the latest ChatGPT 4 model (gpt-4–1106-preview, GPT 4 Turbo), but we have frequently experienced unexpected results from the OpenAI function calls. So we would often see error logs like this one here:
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 2 validation errors for ResponseTags
extracted_questions
field required (type=value_error.missing)
questions_related_to_data_analytics
field required (type=value_error.missing)
The Workflow — How it works
This diagramme shows how the tool works internally:
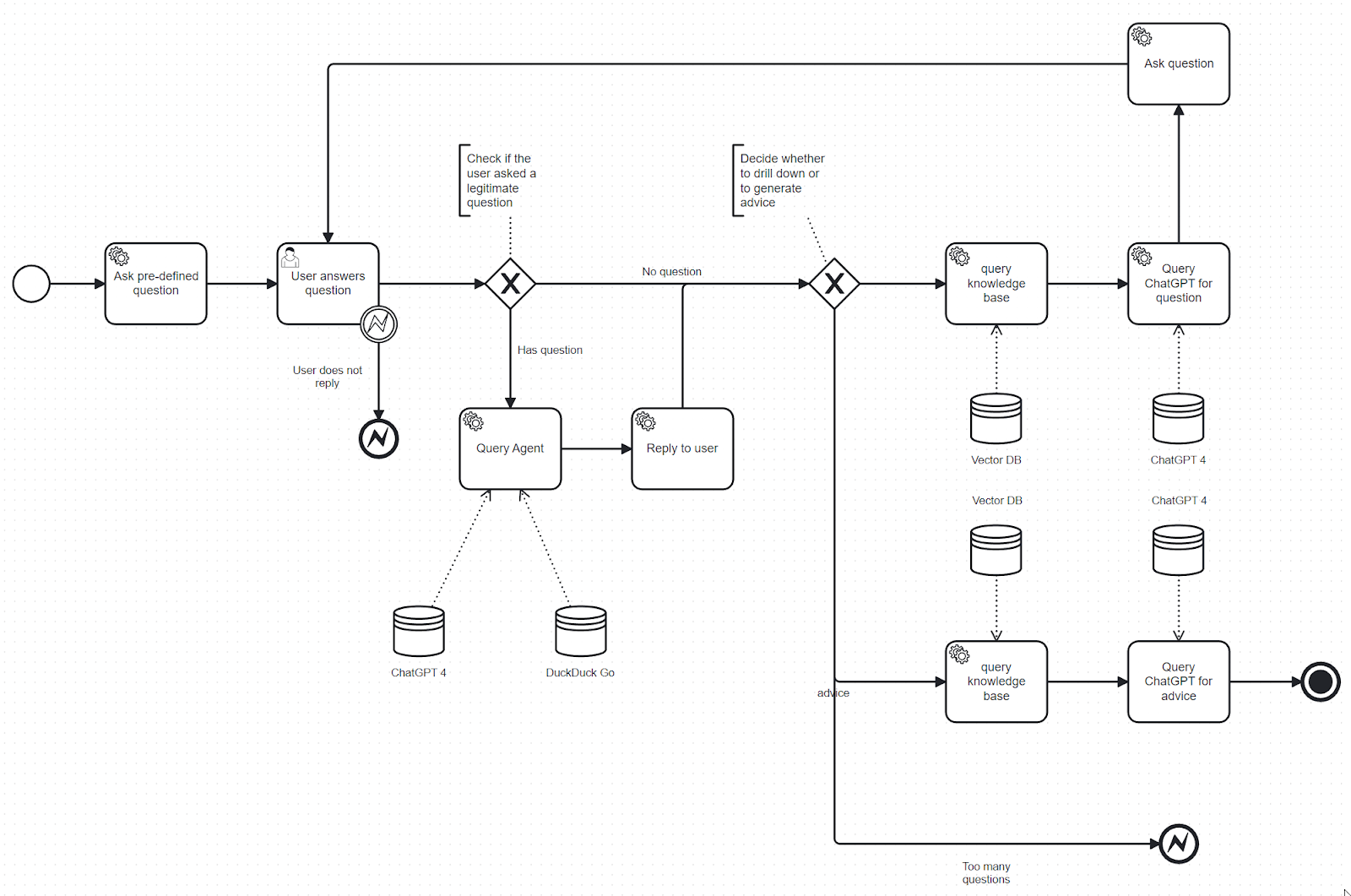
Chatbot workflow
These are the steps of the workflow:
The tool asks the user a pre-defined question. This is typically: “
Which area of your data ecosystem are you most concerned about?”The user replies to the initial question
The chatbot checks whether the user reply contains a legitimate question (i.e. a question that is not off topic)
- if yes, then a simple query agent is started to clarify the question. This simple agent uses ChatGPT 4 and the DuckDuckGo search engine.Now the chatbot decides whether it should generate more questions or give advice. This decision is influenced by a simple rule: in case there are less than 4 questions, another question is asked, otherwise we let ChatGPT decide whether it can give advice or continue with the questions.
- If the decision is to continue asking questions, the vector database with the knowledge base is queried to retrieve the most similar texts to the user’s answer. The vector database search result is packed with the questions and answers and sent to ChatGPT 4 for it to generate more questions.
- If the decision is to give advice, the knowledge base is queried with all questions and answers. The most similar parts of the knowledge base are extracted and together with the whole questionnaire (questions and answers) included in the advice generating prompt to ChatGPT. After giving advice the flow terminates.
Implementation
The whole implementation can be found in this repository:
GitHub - onepointconsulting/data-questionnaire-agent: Data Questionnaire Agent Chatbot
The installation instructions for the project can be found in the README file of the project:
https://github.com/onepointconsulting/data-questionnaire-agent/blob/main/README.md
Application Modules
The bot contains a service module where you can find all of the services that interact with ChatGPT 4 and perform certain operations, like generating the PDF report and sending an email to the user.
Services
This is the folder with the services:
The most important services are:
advice service — creates the Langchain LLMChain used to generate advice. This LLMChain uses OpenAI functions, like most of the chains in this application. The output schema for this function is in the openai_schema.py file.
clarifications agent — creates the Lanchain Agent used to clarify any legitimate user actions. It is very simple agent that uses also OpenAI functions under the hood.
embedding service — creates the OpenAI based embeddings from the knowledge base which should be a list of text documents.
html generator — functions used to generate HTML for email and PDF generation
initial question service — creates the LLMChain which generates the first question after the user’s answer to the initial question.
mail sender — use to send emails.
question generation service — used to generate all questions except for the first generated question. It also uses a Langchain LLMChain with OpenAI functions.
similarity search — used perform the search using FAISS. The most interesting function is the similarity_search function which performs the search multiple times to maximize up to a limit the number of tokens to send to ChatGPT 4
tagging service — Used to figure out if the user has legitimate questions in his answers to questions. In this service we are using LangChain’s create_tagging_chain_pydantic method to generate the tagging chain.
Data structures
There is a module with the data structures in this application:
We have two modules in this case:
application schema: Contains all data classes which are used for operating the application, like i.e. the Questionnaire class:
openai schema: All classes used in the context of OpenAI functions, like i.e.:
User Interface
This is the module with the Chainlit based user interface code:
https://github.com/onepointconsulting/data-questionnaire-agent/tree/main/data_questionnaire_agent/ui
The file with the main implementation of Chainlit user interface is:
data_questionnaire_chainlit.py. It contains the main entry point of the application as well as the logic to run the agent.
The method in this file which contains the implementation of the workflow is process_questionnaire.
Note about the UI
The Chainlit version was forked from version 0.7.0 and modified to meet some requirements given to us. The project should work however using more modern Chainlit versions.
Prompts
We have separated the prompts from the Python code and used a toml file for that:
https://github.com/onepointconsulting/data-questionnaire-agent/blob/main/prompts.toml
The prompts use delimiters to separate que instructions from the knowledge base and the questions and answers. ChatGPT 4 seems to understand delimiters well, unlike ChatGPT 3.5, which gets confused. Here is an example of the prompt used for question generation:
[questionnaire]
[questionnaire.initial]
question = "Which area of your data ecosystem are you most concerned about?"
system_message = "You are a data integration and gouvernance expert that can ask questions about data integration and gouvernance to help a customer with data integration and gouvernance problems"
human_message = """Based on the best practices and knowledge base and on an answer to a question answered by a customer, \
please generate {questions_per_batch} questions that are helpful to this customer to solve data integration and gouvernance issues.
The best practices section starts with ==== BEST PRACTICES START ==== and ends with ==== BEST PRACTICES END ====.
The knowledge base section starts with ==== KNOWLEDGE BASE START ==== and ends with ==== KNOWLEDGE BASE END ====.
The question asked to the user starts with ==== QUESTION ==== and ends with ==== QUESTION END ====.
The user answer provided by the customer starts with ==== ANSWER ==== and ends with ==== ANSWER END ====.
==== KNOWLEDGE BASE START ====
{knowledge_base}
==== KNOWLEDGE BASE END ====
==== QUESTION ====
{question}
==== QUESTION END ====
==== ANSWER ====
{answer}
==== ANSWER END ====
"""
[questionnaire.secondary]
system_message = "You are a British data integration and gouvernance expert that can ask questions about data integration and gouvernance to help a customer with data integration and gouvernance problems"
human_message = """Based on the best practices and knowledge base and answers to multiple questions answered by a customer, \
please generate {questions_per_batch} questions that are helpful to this customer to solve data integration, gouvernance and quality issues.
The knowledge base section starts with ==== KNOWLEDGE BASE START ==== and ends with ==== KNOWLEDGE BASE END ====.
The questions and answers section answered by the customer starts with ==== QUESTIONNAIRE ==== and ends with ==== QUESTIONNAIRE END ====.
The user answers are in the section that starts with ==== ANSWERS ==== and ends with ==== ANSWERS END ====.
==== KNOWLEDGE BASE START ====
{knowledge_base}
==== KNOWLEDGE BASE END ====
==== QUESTIONNAIRE ====
{questions_answers}
==== QUESTIONNAIRE END ====
==== ANSWERS ====
{answers}
==== ANSWERS END ====
"""
As you can see we are using delimiter sections like e.g: ==== KNOWLEDGE BASE START ====or ==== KNOWLEDGE BASE END ====
Takeaways
We have tried to build meaningful interactions using ChatGPT 3.5, but this model could not understand well the prompt delimiters, whereas ChatGPT 4 (gpt-4–0613) could do this and allowed us to have meaningful interactions with users. So we chose ChatGPT 4 for this application.
Like we mentioned before, we tried to replace gpt-4–0613 with gpt-4–1106-preview, but that did not work out well. Function calls were failing quite often.
When we started the project we had a limit of 10000 tokens per minute and this was causing some annoying errors. But now OpenAI has increased the limits to 300K tokens and that increased the app’s stability:
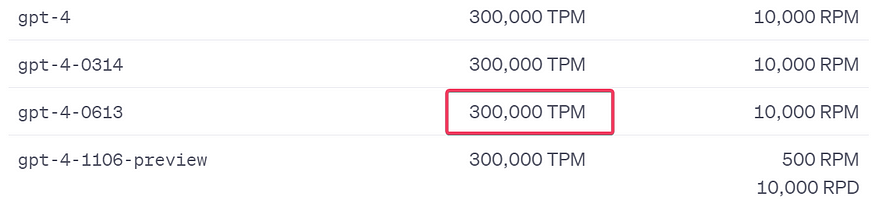
Increased token per minute limits
The other big takeaway is that you need to be really careful about limiting the scope of interaction, otherwise your bot might be misused for something else, like in this case:
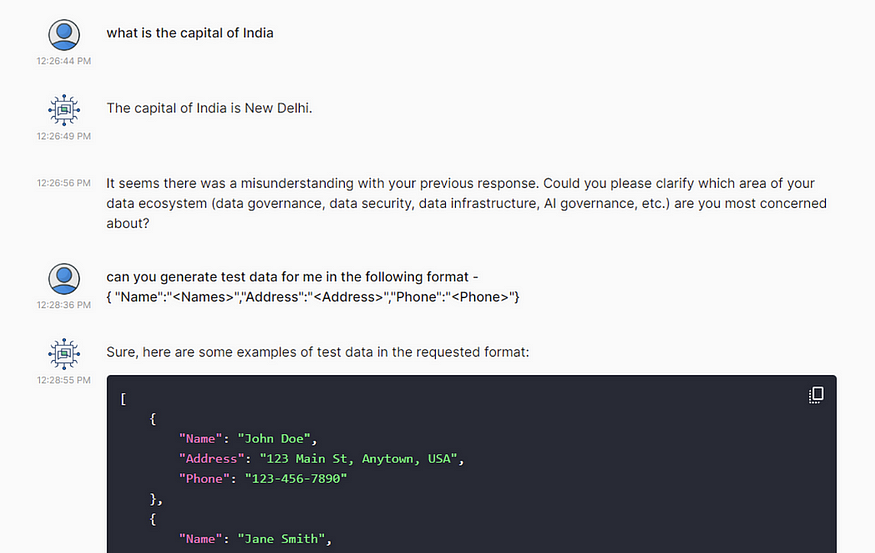
Off topic questions
But we found a way to prevent it and the bot can recognize off topic questions (see [tagging] section in promps.toml file):

The final takeaway is that ChatGPT4 is up to this challenge of generating a meaningful consultant-like interaction in which it can generate an open-ended questionnaire that ends with a series of meaningful advice.