
In this story we will see how you can create a human resources chatbot using LangChain and Chainlit. This chatbot answers questions about employee related policies on topics, like e.g. maternity leave, hazard reporting or policies around training, code of conduct and more.
Since this project was created as a POC, we decided to give it a spin by hijacking the prompts used in this tool, so that the chatbot would tell some occasional jokes whilst answering the questions. So this chatbot should have a humourous spin and some sort of “personality”.
![]()
About Chainlit
Chainlit is an open-source Python / Typescript library that allows developers to create ChatGPT-like user interfaces quickly. It allows you to create a chain of thoughts and then add a pre-built, configurable chat user interface to it. It is excellent for web based chatbots.
Chainlit is much better suited for this task than Streamlit which requires much more work to configure the UI components.
The code for the Chainlit library ccan be found here:
Chainlit - Build Python LLM apps in minutes ⚡️
Chainlit has two main components:
- back-end: it allows interact with libraries like LangChain, Llama Index and LangFlow and is Python-based.
- front-end: it is a Typescript-based React application using material UI components.
A Quick Tour of Our HR Chatbot
Our Chatbot has a UI which initially looks like this in light mode:
Initial Chatbot UI
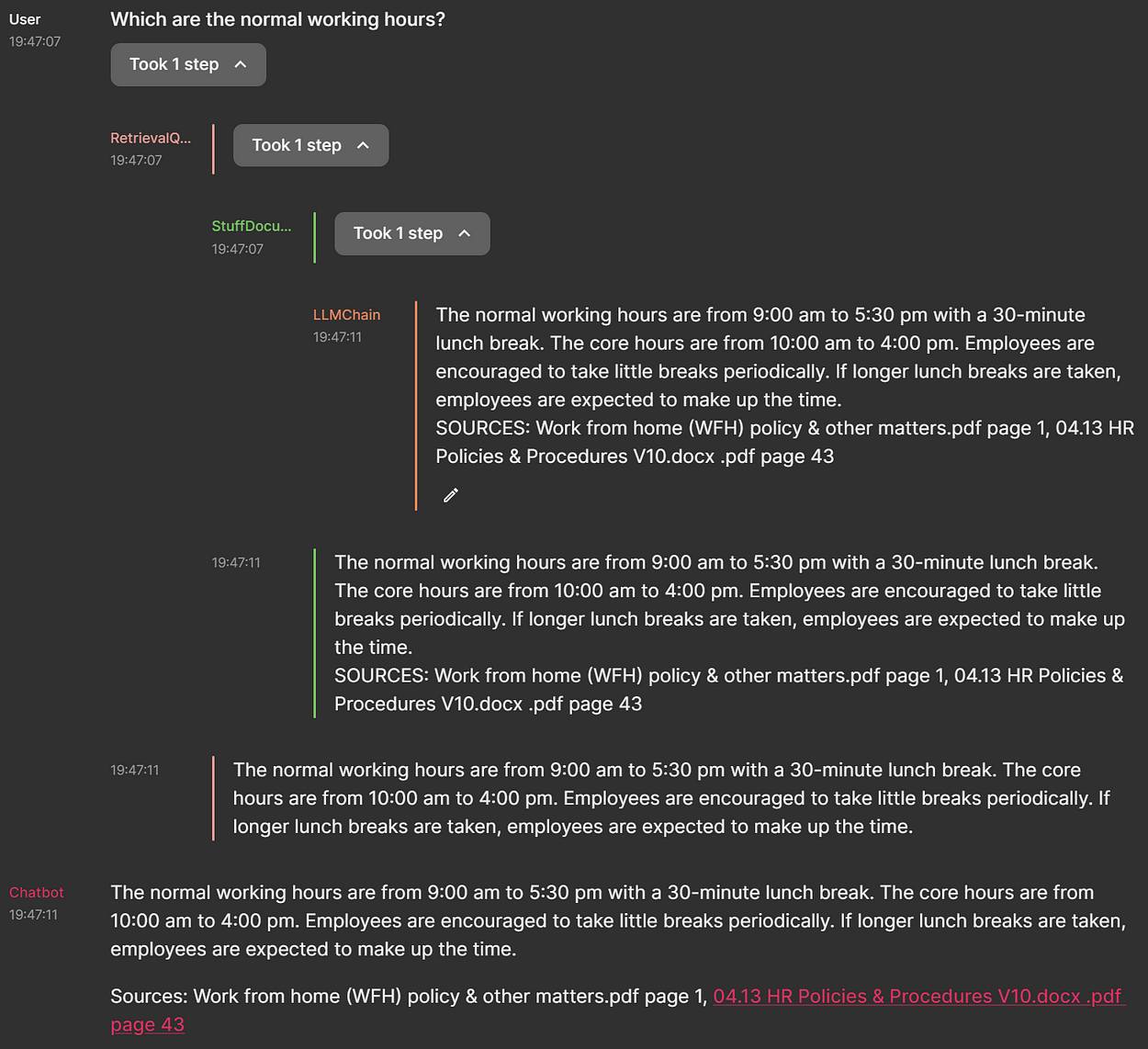
You can then type your question and the result is shown below (using dark mode):

Question on normal working hours
The UI shows you not only the question and the answer, but also the source files. If the text was found, the pdf files are also clickable and you can view their content.
If you expand the steps of the LangChain chain this is what you see:
Thought chain representation
The user interface (UI) also has a searchable history:
Searchable history
You can easily switch between light and dark mode too:
Open settings
Dark mode switch
A HR Chatbot that can tell Jokes
We have manipulated the chatbot to tell jokes, especially when he cannot answer a question based on the available knowledge database. So you might see responses like this one:

Joke when no source found
Chain Workflow
There are two workflows in this application:
- setup workflow — used to setup the vector database (in our case FAISS) representing a collection of text documents
- user interface workflow — the thought chain interactions
Setup Workflow
You can visualize the setup using the following BPMN diagram:
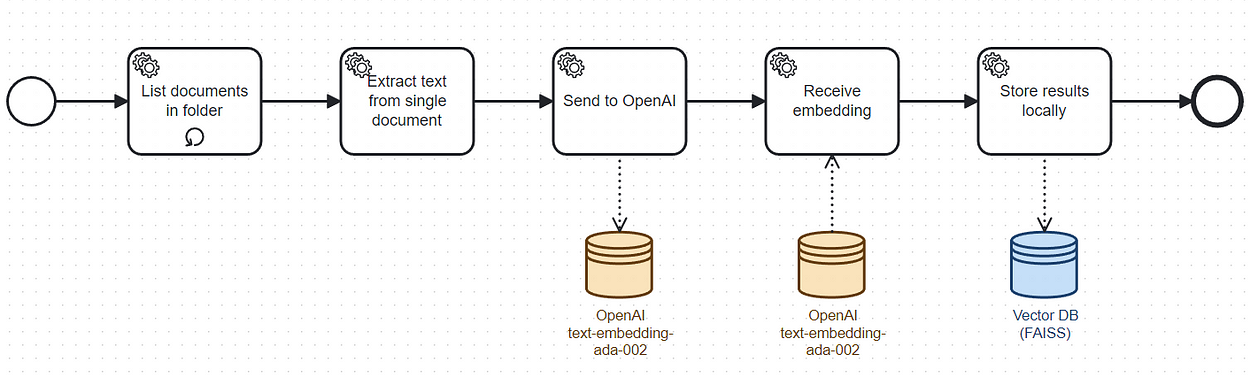
Setup workflow
These are the setup workflow steps:
- The code starts by listing all PDF documents in a folder.
- The text of each page of the documents is extracted.
- The text is sent to Open AI embeddings API.
- A collection of embeddings is retrieved.
- The result is accumulated in memory.
- The collections of accumulated embeddings is persisted to disk.
User interface workflow
This is the user interface workflow:
User interface workflow
Here are the user workflow steps:
- The user asks a question
- A similarity search query is executed against the vector database (in our case FAISS — Facebook AI Similarity Search)
- The vector database returns typically up to 4 documents.
- The returned documents are sent as context to ChatGPT (model: gpt-3.5-turbo-16k) together with the question.
- ChatGPT returns the answer
- The answer gets displayed on the UI.
Chatbot Code Installation and Walkthrough
The whole chatbot code can be found in this Github repository:
https://github.com/onepointconsulting/hr-chatbot
Chatbot Code Walkthrough
The configuration of most parameters of the application is in file:
https://github.com/onepointconsulting/hr-chatbot/blob/main/config.py
In this file we set the FAISS persistence directory, the type of embeddings (“text-embedding-ada-002”, the default option) and the model (“gpt-3.5-turbo-16k”)
The text is extracted and the embeddings are processed in this file:
https://github.com/onepointconsulting/hr-chatbot/blob/main/generate_embeddings.py
The function which extracts the PDF text per page (load_pdfs) with the source file and page metadata can be found via this link:
https://github.com/onepointconsulting/hr-chatbot/blob/main/generate_embeddings.py#L22
And the function which generates the embeddings (generate_embeddings) can be found in line 57:
https://github.com/onepointconsulting/hr-chatbot/blob/main/generate_embeddings.py#L57
The file which then initialises the vector store and creates a LangChain question answer chain is this one:
https://github.com/onepointconsulting/hr-chatbot/blob/main/chain_factory.py
The function load_embeddings is one of the most important functions in chain_factory.py.
This function loads the PDF documents to support text extraction in the Chainlit UI. In case there are no persisted embeddings, the embeddings are generated. In case the embeddings are persisted, then they are loaded from the file system.
This strategy avoids calling the embedding API too often, thus saving money.
And the other important function in chain_factory.py is the function create_retrieval_chain function which loads the QA chain (question and answers chain) :
This function creates the QA chain with memory. In case the humour parameter is true, then a manipulated prompt — that tends to create jokes on certain occasions — is used.
We had to inherit the ConversationSummaryBufferMemory memory class for the memory not to throw an error related to not finding a key.
Here is an extract of the prompt text we used in the QA chain:
Given the following extracted parts of a long document and a question, create a final answer with references (“SOURCES”). If you know a joke about the subject, make sure that you include it in the response.
If you don’t know the answer, say that you don’t know and make up some joke about the subject. Don’t try to make up an answer.
ALWAYS return a “SOURCES” part in your answer.
The actual part of the code related to ChainLit is in this file:
https://github.com/onepointconsulting/hr-chatbot/blob/main/hr_chatbot_chainlit.py
The Chainlit library works with Python decorators. and the initialization of the LangChain QA chain is done inside of a decorated function which you can find here:
https://github.com/onepointconsulting/hr-chatbot/blob/main/hr_chatbot_chainlit.py#L56
This function loads the vector store using load_embeddinges(). The QA chain is then initialised by the function create_retrieval_chain and returned.
The last function process_response converts the LangChain result dictionary to a Chainlit Message object. Most of the code in this method tries to extract the sources which sometimes come in unexpected formats in the text. Here is the code:
https://github.com/onepointconsulting/hr-chatbot/blob/main/hr_chatbot_chainlit.py#L127
Key Takeaways
Chainlit is part of the growing LangChain ecosystem and allows you to nice looking web based chat applications really quickly. It has some customization options, like e.g. allowing to quickly integrate with authentication platforms or to persist data.
However we found it a bit difficult to remove the “Built with Chainlit” footer note and ended up doing so in a rather “hacky” way, which is probably not very clean. At this point in time it is not really clear how a deep UI customization can be done without creating a fork or using dirty hacks.
Another problem that we faced was how to reliably interpret the LLM output — especially how to extract the sources from the reply. In spite of the prompt telling the LLM to:
create a final answer with references (“SOURCES”)
It does not do that at all times. And this causes some unreliable source extraction. This problem can be however addressed by OpenAI’s Function Calling functionality with which you specify an output format, but which at the time of writing the code was not available.
On the plus side, LLM’s allow you to create chat bots with a flavour if you are willing to change the prompt in creative ways. The jokes delivered by the HR assistant are not that great, however they prove the point that you can create “flavoured” AI assistants, that will eventually be more engaging to end users and more fun.





